September 17, 2006
(reposting a broken part)
OOoCon2006 was great, thanks to everyone for the perfect organisation and the kindness of the staff ! As usual, OOoCon was a great moment, the occasion to discuss face to face with people we see nick to nick all the year on IRC. :-)
Many thanks to Radek Dulik + Cedric Bosdonnnat for their conf about GStreamer : we now have a complete plan for the player implementation on Mac OS X, using Quick Time instead of GStreamer, of course. Stay tuned ;-)
Thorsten's conferences about XCanvas and C++ were very interesting too. The pattern Model-View-Controller cannot be bad :-)
Last but not least, for the one interested on Mac OS X native port (without X11) my conf is here :
Mac Port presentation ( .pdf )
As .sxi format is available too :
.sxi format
September 17, 2006 08:15 AM
September 16, 2006
Thursday, just before Shaun and me started the travel for Paris, internet was not working at home :-/
Now Apple Expo is finished, and this news is .. a bit old.
Thanks to my provider. The original message was :
Back from OOoCon2006 ...now Apple Expo ! Just back from Lyon yesterday, ready to go to Paris (Apple Expo ) today :-)
OOoCon2006 was great, thanks to everyone for the perfect organisation and the kindness of the staff ! As usual, OOoCon was a great moment, the occasion to discuss face to face with people we see nick to nick all the year on IRC. :-)
Many thanks to Radek Dulik + Cedric Bosdonnnat for their conf about GStreamer : we now have a complete plan for the player implementation on Mac OS X, using Quick Time instead of GStreamer, of course. Stay tuned ;-)
Thorsten's conferences about XCanvas and C++ were very interesting too. The pattern Model - View - Controller cannot be bad :-)
Last but not least, for the one interested on Mac OS X native port (without X11) my conf is here :
Mac Port presentation ( .pdf )
As .sxi format is available too :
.sxi format
September 16, 2006 09:35 PM
And after looking at cool videos in their tech section (flash required, sorry), I might just consider doing that sometime in the future. Check out Neave.tv
September 16, 2006 10:30 AM
September 15, 2006
mimencode -u EOF
ICAtIGJ1eSBhIGJveCBvZiBjb25kb21zCiAgLSBwcmV2ZW50IHRoZSBhYm92ZSBsaW5lIGZy
b20gYmVpbmcgcmVhZCBieSBteSBtb3RoZXIK
EOF
September 15, 2006 11:10 PM
two entries in a row...
i wanted to share my experience with tabs in tabs in tabs in tabs in tabs (yep, that's a big depth) using irssi in screen in screen in xfce4-terminal in ion3.
look at my screenshot: i had to remember a quite impressive list of shortcuts. to move to the previous/next tab, in order of depth:
Win-k Win-p/n, C-PageUp/PageDown, C-a p/n, C-a a p/n, C-p/n.
i hope you'll never use something like this. honnestly, it's a brain damage.
September 15, 2006 10:44 PM
hi everybody!
i just discovered zsh and i'm getting used to it. i discovered C-r, C-p, C-n and things like that, which are really great, i love the way it works with ! ('!sudo' is replaced by the last command in the history starting with 'sudo' when Enter is pressed, instead of launching that command), etc.
i also love the history shared between all the terminals in my x session, the files matchers (which i'm using to replace a lot of 'find' and 'grep' in my various scripts...).
but what i really love is my prompt:
pts/3(1) 3.-1 gcarrier@vishnu:~/Desktop/INF231/TDe1 15 %
From left to right: pts/3 is the device used by the shell for standard input/output; 1 is the depth of the shell (if launched inside another shell, for example, i becomes 2); 3 is the number of jobs running in background; -1 is the result of the last command (here, a diff); gcarrier is my username, vishnu is the hostname; ~/Desktop/INF231/TDe1 is my pwd (you can see that this prompt is scp-friendly); 15 is the command number in the history; % means i'm a normal user.
To use it, put in your .zshrc:
PROMPT='%y(%L) %j.%? %n@%m:%~ %i %# '
If someone wants to add some colors, i would be pleased to get one's modification.
September 15, 2006 10:19 PM
September 14, 2006
September 13, 2006
This is definitely the year when WiFi became “normal practice” for me - in the hotel, in the conference rooms and grounds of INSA… Having said that, I’m blogging this offline at a tram station for upload later - maybe next year the world will be WiFied?
For now, the second day’s activities at OOoCon are [...]
September 13, 2006 09:01 PM
Cyberpipe guys are again helping stream OpenOffice.org 2006 developer conference talks to the internet. Go check out OpenOffice.org conference media page.
September 13, 2006 09:07 AM
Pride comes before a fall… I thought I was an expert in the Lyon public transport. However, before jumping onto the first bus which comes, it is wise to ensure it is the correct bus. So, an interesting ride into the heart of Lyon and back out again during the rush hour. So much for [...]
September 13, 2006 07:41 AM
Another 6.30 alarm call. I’ve sorted the journey to the conference centre though - a bus, five minute walk, then tram - all one ticket (Eur 1.50 for a journey of up to an hour on any form of public transport). The bus stops all have electronic real-time displays, and the trams look new and [...]
September 13, 2006 07:39 AM
Today is pre-OOoCon day, for mostly internal community meetings. I had planned on a leisurely day with nothing to do until the Marketing project meeting at 11 - then Louis asked me if I could go to Community Council at 9. So much for the lie-in.
So, an early breakfast (classe economique again - but the [...]
September 13, 2006 07:31 AM
September 12, 2006
Yes, it’s OpenOffice.org Annual Conference (OOoCon) time again. OOoCon officially opens to the world on Tuesday, but my journey started on Sunday with a 6.30 drive to the airport, EasyJet from Edinburgh to Stanstead, and lo and behold find myself behind two OOo folks in the check-in queue at Stanstead, and so on to Lyon. [...]
September 12, 2006 08:10 PM
September 08, 2006
Just saw something worth noting. I was on a machine running Office XP and tried to open an Office Open XML (OOXML) formatted document. I don't know why I tried that, but I did.
Word was smart enough to put up the following dialog:

Now, that is something I hadn't seen before. I think we all knew that Microsoft was planning a compatibility pack for enabling OOXML on Office 2003 and Office XP. But my 2002 version of Windows XP knows about OOXML? I guess this wisdom must have come down in a previously downloaded Office patch.
In any case, if you click yes, you are directed to
this page where you are offered a download of "Microsoft Office Compatibility Pack for Word, Excel, and PowerPoint 2007 File Formats (Beta 2)". I had the pre-req's, which included Windows XP SP2 and Office XP SP 3. So downloading a few file conversion filters should be simple and small, right?
Well, simple, but not so small. I was suprised to see that the convertors download was 43MB. That seems a bit large. In comparison, you can
download a complete copy of OpenOffice.org, with included support for ODF documents and the Office binary formats, and the entire product is only a 93MB download. The
0.2 ODF Add-in for Word is only 1MB in size. So why does adding OOXML support to Office XP require a 43MB download?
In any case, once it is downloaded and installed, the integration with Office appears seemless. You can open OOXML files from the Windows Explorer by double-clicking on them, you can browse and load them as expected from the File Open dialog in Office, you can re-save files in OOXML format via the File Save, you can create a new document and save it as OOXML, you can even configure Word XP so the OOXML formats are the default format for all saved documents in Word. In fact, you can do
all of those things that the Microsoft-supported ODF Add-in is not doing.
As reported
earlier, the Microsoft support for ODF puts this ISO standard at a distinct disadvantage, providing no shell integration, removing it from its expected place in the File/Open and File/Save menus, and preventing users from making it the default format in Office.
So, let's update the file format support matrix:
| Criterion |
DOC Format in OpenOffice |
ODF Format in Word 2007 |
OOXML Format in Word XP |
| 1. Format supported in default install |
Yes. |
No. Requires a download and install of separate, unsupported Add-in. |
No, but you are prompted to download a free converter pack the first time you attempt to open an OOXML file |
| 2. File Open integration |
Yes. |
No. ODF is not listed in the default File Open dialog and doing a Control-O will not show ODF documents. However, ODF import is available in a separate menu item elsewhere in the menu system. |
Yes. |
| 3. Save new document integration |
Yes. |
No. In fact no ODF save ability exists in the current version of the Add-in. There is a place holder for the ODF save operation, though it is on its own menu, and would not be shown when doing a simple Control-S to save a new document. |
Yes. |
| 4. Can be made the default format |
Yes. |
No. Although other non-Microsoft formats, such as "Plain Text" can be made the default format, ODF cannot. |
Yes. |
| 5. Simple round-tripping |
Yes. |
No. When an ODF document is loaded, its name is automatically changed and it is made read-only. So loading sampler.odt results in Word having a read-only version of sampler_tmp.docx. Attempting a simple Control-S to save will give an error. |
Yes. |
| 6. Shell integration |
Yes. |
No. |
Yes. |
I tip my hat to Microsoft for the way they have provided OOXML support in earlier versions of Office. Aside from the size of the download, the process was simple and the integration was seamless. That's the way it should be. But what makes them think that customers using ODF format would want anything less than this? That fact that they've been able to integrate OOXML so well only increases the shame in having integrated ODF so poorly.
September 08, 2006 12:23 AM
September 07, 2006
i'm really happy to announce you that i will be at the openoffice.org conference 2006, which is taking place at lyon, france, from monday to wednesday.
i hope it will be funny and interesting, as it makes me miss a few days of studies at the university.
my server, hosting this weblog, will stream the video. i'm quite proud of it.
September 07, 2006 09:41 PM
An updated version of the Microsoft-sponsered ODF Add-in for Word has been
posted. A few weeks ago I had tried out the earlier 0.1 version with results you can read
here and
here.
The Add-in's
Highlights page for the 0.2 version says that "This release is comprehensive with respect to Text, Formatting, Paragraphs, Images, Styles & document metadata scenarios".
So, I gave it a try, installing it with Office 2007 beta 2 running on Windows XP. Here's a summary of what I saw.
The UI integration I previously described and criticized remains unchanged. This will put ODF documents at a disadvantage not only compared to Word's native format, but also compared to other export formats suported by Word such as RTF or even plain text. The only other format that will be ostracized from the File Open menu like this is PDF, and that seems to be because of legal squabbling with Adobe. But what did ODF users do to deserve this treatment?
I tested a conversion with my
sampler.odt file. This is a one-page ODF document that uses a combination of essential word processor features. It is not intended to be an acid test. Unfortunately the 0.2 Add-in failed to load the document at all, hanging with the winword.exe process spinning at 100% CPU. So there appears to be some sort of infinite looping going on.
I tried a few variations of this sample.odt document, removing page elements until I could get it to load without hanging. It appears that the image with the caption may be the source of the problem. I've reported this
defect to the project's bug tracker and will try again when I hear that it is fixed.
September 07, 2006 02:02 AM
September 06, 2006
I was interested by some comments from Anthony Picardi, IDC’s senior vice president of global software research, quoted in Linux-Watch
…open source-software is being used by 71 percent of the developers in the world and is in production at 54 percent of their organizations. In addition, half of the global developers claim that the use of [...]
September 06, 2006 07:05 PM
hi! this is my brand new weblog. i hope you'll enjoy it.
i suppose it'll be written in both french and english.
in this first post, i'd like to tell you that i'm now in the second year of licence, learning comp sci and math, at the French university UJF (Grenoble 1).
i'm starting a magistere, which some kind of super-master.
more personal, i'm playing with my brand new dell d820, a beautiful laptop.
September 06, 2006 03:17 PM
September 05, 2006
Many thank's to Tink ( tink at kde dot org ) who invited me at
OpenDocument Day
This conference is the KDE developer conference, AKA akademy 2006, being held Sep 23-30 in Dublin, Ireland.
Unfortunaly, it will not be possible for me to attend, so the best I can do is to inform and invite other OpenOffice.org people to attend. Mainly - but not only- the one involved in ODF.
You can have a look at the wiki too:
TheOpenDocument@Akademy 2006 Wiki
The best to KDE people for this event !
Eric Bachard
September 05, 2006 11:30 PM
September 04, 2006
Free software advocates and cultural creatives are natural bedfellows - they just have to find each other.
September 04, 2006 12:47 PM
As he stood staring at them, they asked him no questions, for his face told them everything.
'I cannot find it,' said he, 'and I must have it. Where is it?'
His head and throat were bare, and, as he spoke with a helpless look straying all around, he took his coat off, and let it drop on the floor.
'Where is my bench? I've been looking everywhere for my bench, and I can't find it. What have they done with my work? Time presses: I must finish those shoes.'
They looked at one another, and their hearts died within them.
Dickens, a careful student of human nature, provides here a vivid portrait of Dr. Alexandre Manette, who, after being held 18 years in the Bastille, is released, but is unable to adjust to his new freedom, and in times of stress lapses back to the familiarity of his prison labors, making shoes.
We all have been prisoners of Microsoft Office and their proprietary file formats. You may no longer recognize it as a prison, because this cell has been your home for the past ten years, but here is what it looks like:
- Editing a document requires Microsoft Office.
- Since Office runs only on Windows, you also require Windows
- These restrictions lead to a purely heavy-client view of document processing.
- This also leads to a model of programmability that emphasizes storing executable code (macros/script) inside of the document, resulting in years of security nightmares. Here is a typical recital of the known dangers.
- If you didn't want to put script inside your document, you could get to the data via Office automation API's, but this again required a machine running Windows and Office.
- It also emphasizes a unilateral view of WYSIWYG which emphasizes early formatting and layout decisions and de-emphasized semantic richness in documents. For example, "What has WYSIWYG Done to Us?".
- The tools that were created for us to record our thoughts with now instead constrain or even substitute for our thoughts. For example, PowerPoint Panders to our Weaker Points" in the Guardian, and Tufte's "PowerPoint is Evil".
- The above also lead to a stifled market for 3rd party document processing tools. We will never see the value of what was never allowed to occur, but the opportunity cost of the innovation that did not happen in this single-vendor world is enormous.
- This also lead to general lack of competition in the productivity editor market, leading to a decade of buggy products with little innovation.
- We've been locked into a one-size-fits-all offerings of bloated applications. Many people are over-served by Office and therefor are over-paying for functionality they do not need, while others are under-served by the resulting products they cannot afford.
- Functionality has been arbitrarily segregated into three and only three application classes, "Spreadsheet", "Word Processor" and "Presentation Graphics".
The move from proprietary binary formats to new standard formats, like OpenDocument, is a movement from imprisonment to freedom. Although the technical constraints have been lifted, have we really made the mental adjustments necessary to engage our new freedom? Or are we still silently pacing a 10-foot cell in our minds? If we merely recreate our cell walls in XML, then we are still prisoners.
I've been as much a prisoner as you have, and am a creature of habit, so don't look to me for all the answers, but I do have a few thoughts on what this new freedom will look like.
Instead of being opaque black boxes that can only be used on one vendor's system, documents will be transparent. Anyone can access them using whatever operating system and whatever tools they want, and for any purpose they want. Python on Linux, REXX on AS/400, and C# on Windows will all have equal opportunity.
This also implies that document processing will no longer be restricted, technically or by licence, to the desktop. Innovative things will occur on servers. We're starting to see some of that with Writely and wikiCalc. But that is only the beginning. We will see search engines that can intelligently search content for specific MathML expressions, spiders that will collect and aggregate slides from presentations and allow you to share them, document repositories that will automatically check citations in papers and calculate the intellectual social networks these imply, stock brokers that will allow you to download your statements formatted in a spreadsheet, with additional analytics calculated via spreadsheet formulas. Creating, editing, reading, viewing, storing, collaborating will be able to be done anywhere, from your cellphone to the largest servers.
Since the server typically has access to not only your documents, but your organization's as well, as well as easy access to other information about the users, such as your role and group via LDAP, an application can drive workflows that relate the contents of the document to similar content, as well as to you organizational role, and to your business. The companies that unlock the knowledge stored by your knowledge workers in their documents will be leading us into the next decade.
The old walls will fall that once segregated functionality into the arbitrarily prescribed boundaries of "Spreadsheet", "Word processor", and "Presentation graphics". Dan Bricklin is leading the way with his wikiCalc. Is it a Spreadsheet or is it a Wiki? If you have to ask the question then you are still a prisoner. The point is wikiCalc is whatever Dan Bricklin wants it to be. That is freedom to innovate. We will see the arbitrary divisions between application genres become fuzzy and fall away as we all recognize our new freedom.
Document programmability will be turned inside-out. Instead of putting code inside of the document, turning documents into virus vectors, the code will be carefully segregated. Once the code and the data are distinct, we can put the code on the server, where it can be more easily managed, maintained, and secured. This clean separation of code and data will be as important to system stability and security as was protected-mode in the 8026 processor which first enforced this data/code separation at operating system level. I see macro viruses becoming a thing of the past, like smallpox, because the importance of data/code separation will finally be enforced, and users will not be emailing around code disguised in documents.
We will start thinking of documents as data, and as inputs to modules that process data. I see visual design tools that will allow you to drag and drop a document template onto a design surface and expose various fields in the document which can be wired up to databases, web services or other data sources.
I see financial analysts creating financial models in spreadsheets, then converting the spreadsheet into a web app that can then be deployed anywhere to provide browser-based access and execution of the model via any browser.
I see a variety of productivity editors available at a variety of price points, from free, open source ones, to commercial offerings for desktop and other devices, to specialized offerings with extra features for vertical markets, like legal, medical, academic, or scientific uses.
I see an escape from documents-as-pictures, where users sweat over pixel perfection and pray that the applications don't screw them up. Today the end user doesn't worry about font kerning. We rely on the font managers to get this right, and we accept the results, and concentrate on what we, the authors, add to the document. We are freed from that mental burden of kerning. But why stop there? With smarter applications, we will be freed of most or all formatting burdens. We will concentrate on writing, not on styling, and rely on the applications to get the appearance right. This will free our time to give an increased emphasis on semantic richness, putting our knowledge and experience and outlooks and opinions into the document, and encoding it in an way that allows new modes of collaboration and redefines what a document is.
That is a gimpse at what freedom looks like to me. But let's not forget that being freed is not the same as being free. There are those out there who are attempting to merely recreate the same single-vendor closed system we've had for the past 10 years, and redoing it in XML. This may be a comfortable choice to those who have known no other way. But is it really freedom? I look out and see the jailer offering to sell 10-foot apartments to those just released from their 10-foot prison cells. Will you follow?
September 04, 2006 11:27 AM


Above you have Scott #1082, with a first day issue of exactly 50 years ago, September 3rd, 1956. The design is by Victor S. McCloskey, Jr. of the Bureau of Engraving and Printing based on a a small portion of a much larger mosaic, "Labor is Life" (also shown above) by the American artist Lumen Martin Winter. This mosaic was unveiled in 1956 by President Eisenhower at the the AFL/CIO Headquarters in Washington DC .
What a difference 50 years makes! One could write at length about how this stamp portrays a quintessentially 1950's view of the family, the status of women, the industrial base of American labor combined with the influence of depression-era socialist realist art. But it is Labor Day, so I suggest you all get off the computer and start up the grill. That's what I'm going to do.
September 04, 2006 03:32 AM
August 31, 2006
Sticking with Microsoft is a guarantee of a painless upgrade ... not always
August 31, 2006 08:56 PM
August 29, 2006
The Mac OS X Porting Team is proud to announce OpenOffice.org will be present at
Apple Expo (Paris), from 12 to 16 september.
Many thank's to Frédéric Vuillod, Manuel Naudin, Benoit Koch, Sophie Gautier and Cusoon for their help !
I'll be present too the 15th and 16th, a good occasion to show the native version (running without X11) in runtime.
See you !!

Contact : mac@porting mailing list or ericb at openoffice dot org
August 29, 2006 10:14 AM
August 26, 2006
Here is a little code snippet that will allow your python script to access MSN Search.
I’m posting it here in hope that google picks it up and that next person who wants to just google it won’t have to start from scratch.
(I’m not sure how to post it to retain formatting, but since it’s a simple script anyway it doesn’t matter much)
from SOAPpy import WSDL
wsdl_url = 'http://soap.search.msn.com/webservices.asmx?wsdl'
server = WSDL.Proxy(wsdl_url)
params = {'AppID': '***!!!YOUR_API_KEY_HERE!!!***',
'Query': query,
'CultureInfo': 'en-US',
'SafeSearch': 'Off',
'Requests': {
'SourceRequest':{
'Source': 'Web',
'Offset': 0,
'Count': 10,
'ResultFields': 'All',
}}
}
server_results = server.Search(Request=params)
results = server_results.Responses[0].Results[0]
return results
August 26, 2006 10:28 PM
August 23, 2006
David Wheeler, the chair of the OASIS ODF Formula Subcommittee has a good
status update on our work defining the details of the expression language and supporting functions used in spreadsheet formulas. I'd also like to point out some cool work by Daniel Carrera, who put together some code that post-processes the OpenFormula specification (in ODF format, of course), extracts the details of the embedded test cases, then automatically generates an ODF spreadsheet file which executes the spreadsheet functions and verifies correct results. This resulting spreadsheet allows an implementation to automatically test their compliance to the spec. This gives us a self-testing specification, a great labor savings, as well as a demonstration of the innovative things you can do with ODF. Details are
here.
(I note in passing that although the OASIS ODF TC does
all of its working documents in ODF format, the Ecma TC45 does
none of its working documents in OOXML. They continue to use the old proprietary Microsoft binary formats as their working format on the TC. A suggestion -- If they are unable for some reason to use OOXML, then I encourage TC45 to use ISO ODF. They can then download Daniel's code to help generate test cases from their spreadsheet formula documentation and this, I promise you, will save implementors a lot of time.)
Of course, malcontents will never be pleased by our progress, and will portray this progress as proof that we are yet imperfect, and therefore not useful. The first point is obvious, but the second is dubious.
Stephen McGibbon's
blog entry of a couple weeks ago seems to be the Urquelle of this particular line of reasoning. Here's one small quote:
I mentioned that in my opinion, Sun were completely aware that ODF wasn't sufficiently defined to support spreadsheet interoperability as long ago as February 2005 and that the realpolitik inside OASIS was to take advantage of the EU IDA's request to standardise by rushing to be first despite knowing the ODF specification was deficient in at least this area.
Read the rest of his article and you'll walk away with two misconceptions:
- The lack of a spreadsheet formula definition in a file format documentation is unusual, defective and prevents intereroperability
- Spreadsheet formulas were left out because ODF standardization was rushed, for political reasons
Let's take a look at each of these in turn.
First, let's look at the state of the art in spreadsheet file format documentation over the years, with particular attention to how spreadsheet formulas have been documented. As the following table shows, Excel formulas have
never been publicly specified, even though Microsoft has been producing file format documentation for various binary, HTML, XHTML and XML Excel formats for over 9 years. It was only after the ODF TC decided to document our spreadsheet formulas and formed a Subcommittee to do so that Ecma TC45 decided to follow. The FUD followed soon after.
| Date |
Format version |
Formula status |
| 1997 |
Excel 97 Developers Kit (Microsoft Press, 1997) |
not defined |
| ca 1998 |
MSDN CD's in this era had Office file format documentation |
not defined |
| Jan 1999 |
Office 2000's XHTML formats for Excel |
not defined |
| May 2001 |
Office XP's XMLSS format for spreadsheets |
not defined |
| Nov 2003 |
Office 2003's XML Schemas |
not defined |
| Dec 2005 |
Microsoft submits initial "base document" to Ecma |
not defined |
| January 2006 |
Ecma TC45's Working Draft 1.1 |
not defined |
|
February 2006
|
The OASIS ODF Formula Subcommittee is formed to add formula definition to the ODF specification
|
|
| April 2006 |
Ecma TC45's Working Draft 1.2 |
not defined |
| May 2006 |
Ecma TC45's Working Draft 1.3 |
Mirabile dictu! After 9 years of ignoring it, Microsoft finally decides to start defining their spreadsheet formula language. |
So the statement that the lack of a formula language specification is unusual or makes interoperability impossible falls down in the face of 9 years of contrary evidence. Over the years, the industry has managed to have interoperable spreadsheet formulas between different versions of Office as well as between Excel and competing spreadsheets, including 1-2-3, Quattro Pro, OpenOffice, StarOffice, etc., all without ever having a formula specification.
Even though every other spreadsheet file format specification in the past decade failed to document a spreadsheet formula language, the ODF TC knew that we could and should do better. That is why we took the lead and formed a Subcommittee to define, in great detail, with test cases, how spreadsheet formulas, expressions and functions should be interpreted. This is not fixing a problem. This is advancing the state of the art in file format specifications.
They say that imitation is the sincerest form of flattery. If so the ODF community should be blushing with all of this flattery heaped on it. If it wasn't for the continual market pressure that our innovations bring, Microsoft would never have 1) issued a patent covenant for OOXML, 2)brought OOXML before a standards body, 3) started to document their spreadsheet formula language or 4) started to create an ODF Add-in for Office.
So, then what about the statement that ODF was rushed through the standardization process?
Let's look at the numbers. Both ODF and OOXML are derived from pre-existing formats . This is not necessarily a bad thing. This is one source of "implementation experience" and this is beneficial to any standard to have this. But only once the "base document" is submitted to a multi-vendor open standards development organization (SDO) does the true work of standardization begin, including deep technical review of the specification to confirm completeness, conciseness, lack of ambiguity, correct use of formal specification language, ensuring platform independence, encourage flexibility and extensibility, etc. So, I'll start the clock when the base specification is submitted to the SDO, and stop the clock when the SDO approves the standard.
The ODF numbers are clear enough since the 1.0 version is complete. The OOXML numbers require some estimation, since they are not complete, but I'll justify my estimates this way:
- The OOXML Working Draft 1.3 is currently 4,081 pages long. At the SC34 meeting in June we were told by the Ecma Secretary General that more material was coming and that this draft was only 2/3 complete. By my calculations, this gives a final size estimate of around 6,000 pages.
- Predicting the completion date is harder. But we do know that Ecma specifications can only be approved twice a year at Ecma General Assembly which are in June and December. If I were Microsoft I'd really really really want OOXML approved in time for the Office 2007 launch, so I'm predicting Ecma approval will be sought at the December Ecma General Assembly.
Of course I could be wrong on either or both of those estimates, but let's see where the logic takes us. The following table summarizes the time under standardization as well as the rate of standardization (pages/day) for each specification.
| Standard |
Submitted to SDO |
Standard issued |
Days elapsed |
Standard length |
Rate of work |
| ODF |
12 Dec 2002 |
1 May 2005 |
867 |
706 pages |
0.8 pages/day |
| OOXML |
15 Dec 2005 |
31 Dec 2006 (est) |
381 (est) |
6000 pages (est) |
15.6 pages/day (est) |
Now I ask you, who is rushing? ODF took 2 ½ years to standardize 700 pages. Microsoft is trying to standardize a 6,000 page behemoth in just 1 year. I think the argument that ODF was rushed through under political pressure just doesn't stand up to even cursory examination. Honestly, I think this FUD is being spread around as a smoke screen to hide the fact that OOXML is the one that is really being rushed.
August 23, 2006 12:32 AM
August 22, 2006
Christian again did some black magic with event loops, with some code one proposed me to test.
Everything is described on
Christian's wiki
...and
now we have, combined with Pavel's work
real native menus.
It means OpenOffice.org without X11 menubar now looks like other Mac Applications !!
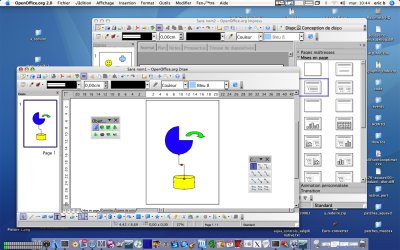
Currently, this bar is not completely active, and using a wrong charset, but this will be fixed soon (click on preview to enlarge) :
We know we have a lot to do to make all menus work, but this is another big step forward we did.
See the
OpenOffice.org without X11 screenshots
link
Next work in progress : add other native controls (sccrollbar, buttons ..etc)
Stay tuned ;)
Contact :
mac@porting mailing list or ericb at openoffice dot org
--
ericb
August 22, 2006 04:04 PM
The
press release puts out numbers of awesome import. We finally have the answers we seek, the science of web analytics and super-duper tools has laid all doubts to rest:
Amsterdam - August 14 2006 - OneStat.com, the number one provider of real-time intelligence web analytics, today reported that Microsoft's Windows dominates the operating system market with a global usage share of 96.97 percent. The leading operating system on the web is Microsoft's Windows XP with a global usage share of 86.80 percent. Microsoft's Windows 2000 has a global usage share of 6.09 percent and is the second most popular OS on the web.
The global usage share of Apple's Macintosh is 2.47 percent and the global usage share of Linux is 0.36 percent.
So what's wrong with this picture? The first thing that hits me is that the survey quotes results to four significant digits. This is unusual in a survey of this kind, since it implies error bars of only +/- 0.005%. Now, what probably really happened here is that 96.97 % of the
sampled users were running Windows. But to apply that level of precision to the entire
population as they do when they call it "a global usage share of 96.97 percent", that is something else altogether. Just because you can calculate a number does not mean that you know a number.
According to their press release, OneStat sampled 2 million users from those who visited their customers . We'll deal with the potential bias issues later. But first let's settle a statistical question, what sample size would be required to know results to 0.005%? This depends on the population size, the number of internet users, which in 2004 was estimated to be 840,000,000 so I'll use a nice round billion (1,000,000,000) as an estimate for 2006.
There are a number of survey calculators on the web. I use
this one from Creative Research Systems. Plug in the numbers into the Determine Sample Size form:
- Confidence level = 95%
- Confidence interval 0.005
- Population: 1000000000
Press Calculate and you will see that the required sample size is around 280 million. So a sample of only 2 million users, even if perfectly sampled, will not allow you to state numbers like 96.97%. It is off by a factor of 100.
So the question then is, how accurate are the results can one expect from "only" 2 million users. You can use the second calculator on that page, and get an answer of around 0.07%. That isn't bad at all and may allow you to say 97.0 +/- 0.1%, which is nothing to sneeze at.
(You can also use that form to discover some interesting facts, like a random sample of 384 people is enough to represent a population of any size to a 5% confidence level. It is this type of asymptotic behavior which allows market research firms to make predictions about the preferences of people all over the world, doing many small surveys, though you may find that you yourself may never be surveyed in your entire life.)
Now all of this is moot if the 2 million user sample is not representative of the total population. The results may be precise to one decimal place, but are they accurate? Are the people who visit the web sites of OneSite's customers reflective of all all web users? Are they typical in terms of country, language, income, age, gender, etc? No supporting info is given.
Sampling bias can be a treacherous thing. For example, let's look at this blog. Over the past few weeks I've received 30,807 visitors, of which 6,512 were running Linux and 14,335 were running Firefox. Based on those numbers, and assuming a world-wide web population of 1 billion, I can issue a press release stating the following:
With 95% confidence Linux has a global usage share of 21.1% (+/- 0.1%) and Firefox as a world wide usage share of 46.5% (+/- 0.1%)
Based purely on the numbers, a have a sample size suffiicent to support the stated precision. But do I think those numbers accurately reflect all web users?
In the end, it is a waste of time to do a survey of 2 million users unless you are rock solid sure that they are randomly selected and representative of the entire population. On the otherhand, if you have a truly unbiased sample, you could tell the OS breakdown of the web to 1% precision with a sampling under 40,000 users.
The lesson? Don't be awed by numbers. There is often less there than meets the eye.
August 22, 2006 02:45 PM
Here's a short tutorial on exchanging MathML between Mathematica and OpenOffice, showing what is possible today, and offering some suggestions for closer integration.
First, start with a new ODF document in OpenOffice. It is often easier to modify an existing document, inheriting its structure and default styles, than to create a new document from scratch. So I believe that a lot of interesting projects with ODF will start with an existing document as a template, and then add or replace content in it.
So, here's what I made, a simple file with a formula describing the Euclidean metric, our old friend the Pythagorean Theorom. Click the image to load the ODF file.
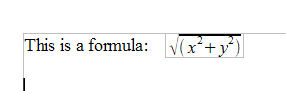
If you rename the ODF file to a .zip extension, and unzip it, you can see the XML files it contains. Always start with the manifest.xml , for your convenience
here, to which I draw your attention to the entry with the type "application/vnd.oasis.opendocument.formula". This, according to Appendix C of the ODF 1.0 specification, is the registered MIME type of an ODF formula document. So that sounds like what we want. Let's replace that equation with something else.
So into Mathematica we go. Suppose I want to calculate the indefinite double integral of the Euclidean metric. Why not? This is something I'd rather not do by hand, but I know Mathematica can quickly give me the answer:
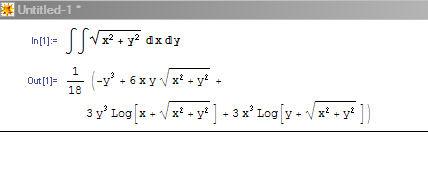
Now I really don't want to retype that result into OpenOffice. So, what can I do? I can use Mathematica's ExpressionToMathML function to turn the above into MathML. When I do that I get MathML like
this.
Let's see now what happens if I simply drop that content in as a replacement for the original content.xml in the ODF file. Here's what I get (click the image to open the ODF file):
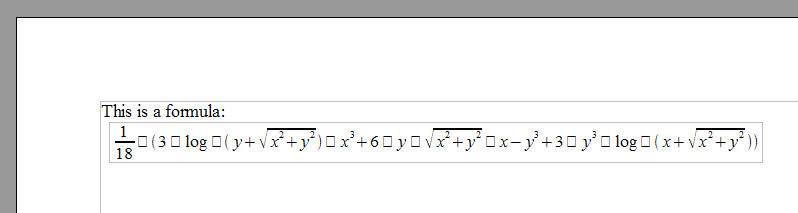
So we got something, but it is not quite right. I'm seeing some little hollow boxes, usually an indication of an unprintable character. What's up with this?
A closer look at the XML generated from Mathematica shows that these boxes are being displayed whenever the MathML uses the XML character entities corresponding to
section 6.2.4 "Non-Marking Characters" of the MathML specification. This includes things like "InvisibleTimes" which handles cases where adjacency represents multiplication (xy == x*y). Using these characters provides hints to the application that can help it optimize its rendering and editing, but they should not be displayed.
In any case there appears to be a bug in OpenOffice 2.0.3 where it tries to display these characters and finds they don't map to any printable Unicode character. No big deal, I will enter a bug report on that later. But for now I can easily clean this up by defining a new function in Mathematica, ExpressionToOO, defined as follows:
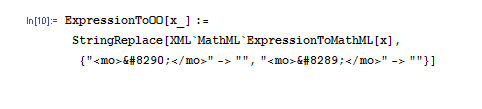
(Note I didn't name this "ExpressionToODF", since strictly speaking the ODF specification allows MathML 2.0, including the non-marking characters. This function is specifically to work around an OpenOffice bug. It outputs valid MathML, simply removing the non-marking characters which OO doesn't understand.)
So, back to Mathematica, I run ExpressionToOO, grab that XML and inject that XML into the ODF document, and we get the following (click to open the ODF file):
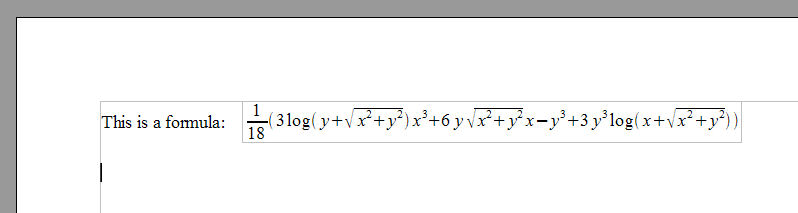
That's what we want! For those who are interested, the complete Mathematica notebook is here:
Session.nb.
As you can see, this isn't rocket science, though no doubt it may be useful to rocket scientists. Consider this a little "proof of concept". Real end users will not be going around unzipping ODF documents and copying XML around. There needs to be some additional integration work to make this process simple and joyful. For example:
- A Mathematica function that automatically inserts a formula into an ODF document
- A OpenOffice add-in that lets the user automatically browser formulas from Mathematica and insert them into the current working document.
- Clipboard level exchange of MathML between OpenOffice and Mathematica
- An export filter from OpenOffice to export to the XHTML+MathML+SVG profile defined to the W3C. This, combined with Firefox, would provide kickass scientific publishing using open standards and tools.
Note that I'm using here Mathematica just as an example. There are over 100 MathML supporting applications out there, both commercial and open source. I'd be interested in hearing what other ideas people have for workflows involving ODF editors and other tools that work with the standards ODF includes, not just MathML, but SVG, XForms, etc. Let's demonstrate the value of open standards working together.
August 22, 2006 12:31 PM
Last winter I tried to write case study how Cyberpipe managed to create OOoCon 2005 media page. After finishing the paper I wanted to add some extra stuff to it and such but since I didn’t touch it for last 6 months or so I will just release it into wild and hope someone finds it useful. I can also provide original OpenOffice.org file upon request if anyone needs it.
OOoCon 2005 media case study.
A big thanks goes to all Cyberpipe members who helped me write it.
August 22, 2006 12:02 PM
August 21, 2006
I. OpenOffice.org Conference (OOOoCon 2006) in comming up, September 11-13th in Lyon, France. The last day starts with a panel discussion of ODF topics, and follows with a track dedicated to ODF. I'm on at 14:00 with a presentation with the exciting title, "A Technical Comparison: ISO/IEC 26300 vs Microsoft Office Open XML (Ecma International TC45 OOXML WD 1.3)".
The abstract is:
Two XML office file formats have been pressing upon our attention, the OASIS OpenDocument Format, recently standardized by ISO, and the Draft Ecma Office Open XML. This presentation will review history of each, the process that created them, and examine each format to compare and contrast how they deal with issues such extensibility, modularization, expressivity, performance, reuse of standards, programability, ease of use, and application/OS neutrality.
II. KDE enthusiasts get together two weeks later, in Dublin, for their aKademy 2006. Tuesday the 26th will be OpenDocument Day. I'll be there, and will give a lighting talk on something, probably related to some ODF programmability API ideas I've been having.
III. If you didn't see it yet, Rick "Schemetron" Jelliffe has an interesting post over at O'Reilly looking at ODF and OOML documents from the perspective of XML complexity metrics. This is a topic which Rick has done a good deal of work with in the past, so it is interesting to hear what he has to say. Did I see something there about OpenOffice loading documents faster than Office?
IV. The ODF Formula Subcommittee has set up a wiki page on our work defining OpenFormula. A lot of good information is there. This page will be updated with the latest status, so you'll want to make it the first place to go for the latest info on our progress.
August 21, 2006 04:46 PM
August 20, 2006
I work in a house with glass walls. Not literally, of course. The cost to air-condition such a house would be prohibitive. I mean that working on standard in OASIS is a public action, with process transparency and public visibility. The public doesn't see merely the end-product, or quarterly drafts, they can see (if they are so inclined) every discussion, every disagreement and every decision made by the TC, in near real-time. Our
meeting minutes for our TC calls are posted for public inspection. Our mailing list
archives, where most of the real work occurs, is there for the public to view. The
comments submitted by the public are also available for anyone to read. This information is all archived from when the TC
first met back in 2002, all the way to the discussions we're having today on
spreadsheet formula namespaces.
One side effect of this openness is it makes it very easy, trivial in fact, for our critics to simply read our mailing list, look for a disgreement or discussion of an issue, and repeat our words, usually out of context. Cut & Paste. This is certainly the most efficient way to criticize ODF since it minimizes the amount of thinking required. However, this is a bit tedious, especially when this is applied so asymmetrically, as I shall now explain.
Ecma TC45, the committee producing Office Open XML (OOXML), does not operate in a transparent manner. They do not have a public mailing list archive. They have not published their meeting minutes. The comments they receive from the public are not open for the public to read. The public has no idea what exactly the TC is working on, what issues they think are critical, whether the TC is in unanimous agreement, whether there is spirited debated or whether Microsoft dominates and decides everything. The fact that they have not yet sent OOXML for an Ecma vote is proof that believe the specification is not yet ready for standardization. But we know no details of what exactly is lacking, what problems are being fixed and, more importantly, what defects are being allowed to remain.
And in this way, the ODF bashers take advantage of our openness, while holding their deliberations in obscurity. They throw rocks at our glass house while hiding in the shadows.
So clearly, this openness at OASIS has its downside. But honestly, I wouldn't trade it for any alternative. Making a standard, especially one this important, is a privilege, not a right. The public deserves to know what goes into a standard, the same way and for the same reasons they deserve to know what goes into legislation. I relish this scrutiny because I know it makes us stronger.
Sun's Simon Phipps has posted his
keynote from the recent OSCON conference. The topic was the "Zen of Free" and, among other goodies, Phipps lists 5 requirements for "full support for fully open standards", of which I quote the 4th, since it states the point better than I have:
...the standard [Phipps here speaking generically and not about any specific standard] should have been created transparently. Just as an open source community looks with concern on a large, monolithic code contribution, so we should be wary of standards created without the opportunity for everyone to participate or, failing that, with a full explanation of every decision that was made in its construction. Without that there's a chance that it's designed to mesh with some facility or product that will be used to remove our freedom later.
Another way to attack openness is to do it with legal restrictions. For example, we're seeing an awful lot of references to a year-old performance evaluation of an atypical spreadsheet file, and using that to make the ridiculous claim that the ODF format itself is too slow. I'd love to dispute that claim and show it for what it is. I'd love to show that for most common document sizes, ODF documents are actually smaller and faster to load and save than OOXML documents. I'd love to show you all this, but I can't. Why? Because Microsoft won't let me. The only implementation of OOXML is the Office 2007 beta, and the End User Licence Agreement (EULA) has this language:
7. SCOPE OF LICENSE. ...You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval
So, our critics can quote benchmark results about ODF running in OpenOffice, but we can't quote numbers about OOXML running in Office. They can read our mailing lists and quote us discussing ODF issues as we address them, but we cannot even see what they are working on.
What should we make of all this? I suggest that no specification is perfect. That's why we have version numbers. The question you need to ask yourself is what leads to a better specification, full and open public discussion and scrutiny? Or something rushed through the process behind closed doors? You know what the issues with ODF are, and you'll continue to hear the same small list over and over again. But this is a shrinking list, as the ODF TC experts address these issues. But do you know what the issues with OOXML are, the reasons why Ecma TC45 has not yet put forward their specification as an Ecma standard? What do their experts say when speaking candidly about their specification? The public simply doesn't not know. Do we assume silence means perfection? I don't think so.
August 20, 2006 07:17 PM
In this post, I will look at the history of Vector Markup Language (VML), how it lost out to the W3C's SVG back in the 1990's, but has come back from the dead, showing up in the draft Ecma Office Open XML (OOXML) specification. I offer some opinions on why this is a bad thing.
First, a bit of history. The field is vector graphics, the type of graphics composed of lines and shapes and background fills, the type of graphics that scales nicely to different sizes/resolutions, and different devices, as opposed to raster graphics which is a bunch of pixels such as a GIF or JPEG file. This is a gross oversimplification, but it will suffice.
Vector Markup Language (VML) was an XML vocabulary for vector graphics
submitted to the W3C by Microsoft and others back in mid-1998. I will not comment on its quality or merits, but merely note that it was rejected by the W3C in favor of Scalable Vector Graphics (
SVG) specification which became a W3C
Recommendation (that's what the W3C calls their standards) in 2001. Since then, SVG 1.0 was upgraded to SVG 1.1. in 2003 and several mobile profiles (SVG Tiny and SVG Basic) were created. SVG has native support in Firefox and Opera, with Plugins available for most other browsers. There is support on mobile phones and PDA's. A search of Amazon.com shows
19 books dedicated to SVG. The
SVGOpen Conference has been going for 5 years strong. This all adds up to SVG being an established, open standard, widely implemented with a thriving implementor/user
community and signs of continued innovation. It is a standard with a past, a present and a future.
But what ever happened to VML? VML has been a dead-end, from a standards perspective, for 8 years now, an eternity in web time. I was not able to find any VML books on Amazon. I could not find any VML conferences (unless one counts the
Virgina Municpal League's get-together at Virgina Beach in October). However, there is some lingering VML support in Internet Explorer and Office. Developers still use VML to target those applications, but I wonder, is it done out of preference or out of necessity? Although it is the users who are
portrayed as dinosaurs for not upgrading to Office 2003, doesn't it seem like Microsoft Office and Internet Explorer are the ones in need of an upgrade? They should join the rest of the world and start using SVG rather dragging along a dead spec.
But it is worse than this. I wouldn't have bothered writing this just to point out something you already know, that Internet Explorer slowly or never adopts relevant web standards. The thing I wish to bring to your attention is that VML, the same VML rejected in 1998, is now being proposed as part of the draft Ecma Office Open XML. Take a
look for yourself (warning, 25 MB specfication download!).
Section 8.6.2 of the spec (Ecma Office Open XML, Working Draft 1.3) says:
VML specifies the appearance and content of certain shapes in a document. This is used for shapes such as text boxes, as well as shapes which must be stored to maintain compatibility with earlier versions of consumer/producer applications.
How should one parse "earlier versions of consumer/producer applications"? Is this a circuitous way of saying "MS Office and Internet Explorer"?
Now take a look at Chapter 23, VML, pages 3571-3795 (PDF pages 3669-3893). We see here 224 pages of "VML Reference Material", which appears to be a rehash of the 1999 VML Reference from MSDN, and in this form it hides itself in a 4,081-page OOXML specification, racing through Ecma and then straight into ISO. Is this right? Should a rejected standard from 1998, be fast-tracked to ISO over a successful, widely implemented alternative like SVG?
Why should you care? It is all about reuse.
- If a standard reuses an already successful standard, it reuses the collective community wisdom that went into making that standard. It also reuses the considerable editorial effort in writing, editing and reviewing a technical specification. Reusing this effort lets the TC focus their time on on truly innovative aspects of their specification, and leads to a higher quality standard.
- When you reuse a standard, you allow implementors to reuse the experience and knowledge they have already developed around that standard. Remember the 19 books dedicated to SVG? There is a lot of SVG knowledge out there. Why waste it?
- Reusing an existing standard, especially a popular one like SVG, allows implementors to reuse the various code bases, both commercial and open source that support it. Why reinvent the wheel? Do you really want to rewrite a vector graphics engine? SVG has several good open source libraries including Apache Batik and librsvg.
Use SVG and you get reuse on three fronts. Stick with VML and the only thing that is reused is Microsoft's legacy code. Using SVG is clearly the better choice.
I suggest that Ecma TC45 investigate this issue and consider moving off of VML and move to SVG, or at least demonstrate why it is impossible to do so. Why does the world need yet another XML vector graphics standard? If there is something missing in SVG (which I doubt) then why not work with the W3C to propose a enhancement for SVG rather than re-proposing the VML standard which was rejected back in 1998?
Again, I make no technical argument why SVG is or isn't superior to VML. I merely note that SVG has been an adopted W3C standard for 5 years now and should have a presumption of suitability for the task, especially over a specification which were rejected 8 years ago.
(Full disclosure, I sit on the OASIS OpenDocument Format (ODF) TC. ODF uses SVG. This is a good thing.)
August 20, 2006 07:14 PM
In this entry I will:
- Discuss the official and unofficial constraints on the development of Ecma Office Open XML.
- Consider what it means for the standard, with reference to the inductive logic game of Zendo.
- Take a dive into Art Page Border as an example of how OOXML is overconstrained and why that causes problems.
- Show how to do Art Page Borders better, while still preserving compatibility with legacy documents.
It is the type of response that is designed to end debate -- "Backward compatibility with billions of documents produced over decades". Variations of this occur everywhere. Rather than cite them all, a
simple query will bring up a typical selection.
Note that Microsoft has not claimed that the Draft Office Open XML (OOXML) formats are 100% backwards compatible with Office binary formats, nor have they demonstrated it. They are merely claiming that it is important to do so.
However, I'm not sure that Ecma TC45, the group standardizing OOXML, has the goal of producing a format backwards compatible with the legacy binary formats. In fact, their Terms of Reference (ToR) document states (with my emphasis):
The goal of the Technical Committee is to produce a formal standard for office productivity applications within the Ecma International standards process which is fully compatible with the Office Open XML Formats. The aim is to enable the implementation of the Office Open XML Formats by a wide set of tools and platforms in order to foster interoperability across office productivity applications and with line-of-business systems. The Technical Committee will also be responsible for the ongoing maintenance and evolution of the standard. [Ecma/GA/2005/154]
In other words, their official charge seems to be to produce a spec which is fully compatible with Microsoft's initial submission, a goal that should not be too much of a stretch to achieve. Also, since Draft OOXML is only supported by the Office 2007 beta, the number of legacy documents is far less than 1 billion, in fact lower by several orders of magnitude. Further, as this standard is still a Draft in Ecma, and subject to change, so experts, including Gartner, are recommending caution, that "companies cannot really start to seriously examine them". But I digress...
There is a game called Zendo, where a player, called the Master, forms in his mind a secret rule which governs the selection and arrangement of objects (often small colored blocks or shapes). Arrangements which conform to the secret rule are said to have 'Buddha nature". The other players take turns trying to select and arrange their own blocks to conform to what they think the secret rule is, to which the Master will acknowledge success or failure. The winner is the one who first guesses the secret rule, which might be something "an odd number of blocks, at least one of which must be red".
Microsoft is playing Zendo with the Office XML specification. The Master has formed a secret rule. He calls it, "backwards compatibility with billions of office documents". But since the file format documentation for the proprietary legacy binary formats has not been made public, the rule might as well just been called "Buddha nature". It is just as opaque. We have no way of judging whether any specific requirement of the Draft OOML is there to support backwards compatibility, or whether it is just there for the convenience of the Office development team. Or in fact whether it is there to raise barriers to non-Microsoft implementors. How could we know, since the main constraint is via reference to information that isn't public? Does Ecma TC45 itself even have access to the binary format specifications? How are they able to properly judge what is done in the name of compatibility? Do we all just take Microsoft's word for it?
The key point in my mind is that legacy compatibility may be a constraining factor, but it is not a determining factor. There are many, perhaps an infinite number of possible markups which would be compatible with the legacy formats, meaning the legacy documents can be unambiguously transformed into the new XML format. The constraint is that they must be mappable, not that they must be identical. Among the set of possible formats, some will be elegant, some sloppy, some bloated, some sparse, some which will be easy for others to implement, some designed to minimize conversion work for just one vendor, etc. In other words, this can be done well, or it can be done poorly. The constraint of compatibility is not justification for everything.
An example may make things clear. Word has a feature called Art Page Borders. If you are like me, you've gone 15 years without seeing or using this feature. But it is there, under the Format/Borders and Shading menu, on the Page Border tab.
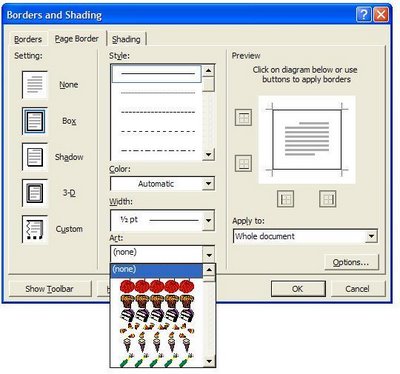
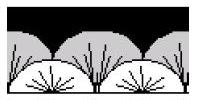
The markup needed to define these borders is covered in section 19.17.4 of the 1.3 Draft Ecma Office Open specification (pages 1617-1671 in spec page numbers, 1715-1769 in the PDF's numbering scheme). Here we see descriptions and images of 200 hundred or so Art Page Borders. The images are heavily weighted to Western even Anglo-American celebratory icons, things like gingerbreadmen for Christmas or slices of Birthday cake, pumpkins for Halloween, or images of Cupid for St. Valentines day, or globes which are neatly centered on the United States. Aside from such a cultural bias, these images are ambiguous. For example, this image is said to be a shell pattern and is called "archedScallops". Does this look like scallop shells to you? To me it looks more like five people bent over to touch their toes, as viewed from behind.
I think it is a legitimate concern that a document format with such obvious cultural biases is moving forward toward an international standard. Further, I am concerned that the specification includes any sizeable collection of clipart. What rights does the implementor have to reproduce this clipart. Keep in mind that Microsoft's "Covenant Not to Sue" covers patents, not copyrights. I haven't seen anything that would grant implementors of OOXML a royalty-free copyright to reproduce this clipart. Is the specification hard-coded to use clipart which we cannot copy? Please, someone correct me if I'm mistaken in this.
All of these problems (spec bloat, cultural bias, non-extensibility, copyright concerns) can be solved by one simple mechanism. Instead of having ST_Border be a fixed enumerated set of values, have it include only a small number of trivial values like the basic line styles, and have everything else (all of the Art Borders) be stored as a separate image file in the document archive.
So, if you load a Word XP document that uses the "candyCorn" Page Border, then when you write it out to Office Open XML, you include a single frame of that art in the zip file and have the XML document reference that image for the border, repeating as necessary. This solution has several advantages:
- It removes bloat from the spec. No need to document 100's of page border clip art
- It lowers the barrier to implement. No one is required to implement 100's of border styles. They are all generated on-the-fly based on images stored in the document.
- Copyright concerns are eliminated.
- Is an extensible approach. An implementation can include different or additional border styles according to their business and cultural requirements.
- It is compatible with legacy documents. Any existing Word binary or XML document can unambiguously be mapped into this scheme
Of course, this approach would require some code changes in the Word product itself to support this extensible mechanism. But remaining backwards compatible with the Word product was never a stated constraint. No one ever said that the goal of Ecma Office Open XML was to reduce the cost for Microsoft to implement. It is all about the legacy documents, right?
So there it is, one example to illustrate a point that can be repeated over and over again. The need to support legacy document is a constraint, but not the sole determining factor. Among the potential universe of compatible XML formats for Office are those which are flexible, easy to use, easy to implement, as well as those which simply perpetuate the status quo and vendor lock in.
August 20, 2006 07:13 PM
Back since a week, a lot of changes in Mac OS X native port of OpenOffice.org have been done while I was on holidays !!
I first want to say thank you to
Christian Lippka for all the work he recently did with bitmaps: his work is great, and helped a lot.
A big thank you Christian !!
Of course, I don't forget Pavel, Pierre ...and all other people of the Mac Team, doing a wonderfull work for the port: thank you too ! :-) Using these changes, OpenOffice.org runs without X11 (using Pavel tips with droplet).
How ? Just have a look... ( Terminal.app replaced xterm, to proof I really didn't use X11)
First example, using draw (click the preview to enlarge):

Second, opening Business cards sample in Writer (click the preview to enlarge):

To satisfy the curious ~ 70 other screenshots can be found here :
Other screenshots of OpenOffice.org on Mac OS X without X11 Note: don't forget to ask me if you want to use these screenshots.
Of course , a lot has to be done, and currently, we have still important problems to solve :
- event loops
- complete ATS font server implementation
- implement all missing methods in aqua
- complete windowing management (some parent issues)
- practice intensive debug
- (lot of other tasks ... )
The most important:
we need help from experimented Carbon developers.
If you have a very good Carbon API experience and want to contribute on OpenOffice.org, please contact us !
To be continued ...
--
ericb
Contact : mac@porting mailing list or ericb at openoffice dot org
August 20, 2006 12:47 PM
August 19, 2006
Summary: In this post I will look at MathML, a web standard for displaying mathematical equations. I will show how well established it is on the web, how it is integrated into ODF, and how Microsoft has decided to go off in another direction with OMML, another "stealth" standard hidden in their 4,000 page Office Open XML specfication, but little mentioned. As I did with my prior analysis of their reliance on the rejected
VML specification, I will show why this is a bad thing.
I've been reading
Math You Can't Use: Patents, Copyright, and Software a book by Ben Klemens, Guest Scholar at the Brookings Institute. It examines the current state of software patents in U.S. and the abuses thereof. He blends his legal and economic policy background with his insights as a programmer to give a perspective worth hearing. Mind you, I don't agree with him on many points, and in fact I found the book infuriating at times, but he does make a serious argument and I respect that. In any case I like to have my opinions challenged every now and then. It keeps the mind limber.
Although I am not going to talk about patents and copyrights today, I will steal the title of this book and talk a bit about math, the kind you can use as well as the type you can't. The topic for today is MathML.
MathML is a web standard from the W3C, an XML vocabulary for representing the structure and content of mathematical expressions. In other words, it represents equations for display, especially complicated expressions with integrals, summations, products, limits and all the Greek you can throw at it.
If you are running Firefox and have installed the
math fonts then you can get an idea of its capabilities by loading MathML-enabled pages right now, like
this one. If you are running Internet Explorer, then sadly you lack native support for MathML, but a
browser plugin is available.
MathML 1.0 dates back to 1999, and has been revised through MathML 2.0 (second edition) in 2003.
There are about
100 implementations of MathML if you count producers, consumers and editors, including the powerful software used by working mathematicians and scientists like
Maple and
Mathematica.
The W3C has made a special effort to get the various MathML vendors together to evaluate how well they handle MathML and this is reported out in their
Implementation and Interoperability Report .
Where MathML is supported natively, such as in Firefox, it will render along with the text, and not merely as an embedded GIF image. So, it will scale to different screen resolutions and print well. In theory, since it is just text markup in the page, it can be indexed by an intelligent search engine, though I am aware of none that do this currently. (Is there any use for a Google search of all web pages that include a 3rd degree polynomial inequality? I wouldn't want to be the first to say "No".)
MathML also is the key to enabling better support for mathematics via screen readers and other assistive agents. When a visually impaired user is presented an equation in the form of a GIF or other image format, they are left out. But put the formula in MathML and the possibilities look better. The work is not complete yet, but progress is being made. For example
this report from CSUN 2004 and NIDE's
MathML Accessibility Project.
Further innovations are seen at sites like Wolfram's
MathMLCentral where we see web services for creating, displaying, or even integrating MathML expressions, using their Mathematica program as the backend.
For the above, and many other reasons, MathML was the only logical choice for us to use to support equations in OpenDocument Format (ODF). With such a thriving ecosystem of producers and consumers, with support the tools used by academia and industry like Mathematica and Maple, strong support in web browsers like Firefox, with the accessibility initiatives around it, I don't see how you could argue otherwise. MathML is the way the web does math.
But the choice of MathML is more than just a fashion statement. It has practical significance and enables opportunities for innovative workflows around mathematical document production. If you create an equation block in OpenOffice, it saves the equation as a standalone MathML XML document in the ODT document archive. This makes it very easy to access, read, replace, etc.
We should be thinking about workflows like the following:
- Do your complicated calculations in a tool like Mathematica
- When you get the final results you want, export it to MathML, for example, using Mathematica's MathMLForm[ ] function.
- Copy the MathML into an ODF document archive
- Take the ODF document and complete the prose write-up of the document in OpenOffice
- Share the draft with colleagues, review, etc., in the editable ODF format
- When ready to publish, export to XHTML with embedded MathML preserved for the equations, and embedded SVG for the charts.
- Users can then view in Firefox or Internet Explorer (with extra plugin)
We're not quite there yet, end to end. Step #6 in particular is not working as I'd expect in OpenOffice 2.03. But you get the idea. There is opportunity for fame glory and perhaps some profit to the person or company who provides an end-to-end mathematical editing and publishing solution based on
open standards.
So, in this happy world I've described, what is missing? If you guessed "Microsoft Office" then you guessed correctly! Even though MathML is a 7 year-old standard, widely implemented, supported by the leading mathematical tools, the preferred format for publishing math on the web, etc, etc., (the mantra should be familiar), Microsoft has ignored it and instead is pushing forward a new competing format in their Office Open XML (OOXML) specification rushing through Ecma.
The new math markup format is called OMML and you've probably never heard of it. You can check Google, you can check Wikipedia, you can check MSDN. You won't find it. In fact, I'm not even sure what OMML stands for since the acronym is not defined in the spec. But it is there, nestled away in the 4,081 page draft OOXML specification as the markup that "specifies the structures and appearance of equations in the document", Section 25.1, all 93 pages of it.
OMML is not MathML, though it does the solves the same problem. But if you use OMML, it will not work with Firefox, with Mathematica, with OpenOffice or with any of the other 100 applications that support MathML. OMML works with Office, and that's it. One door in, no doors out.
Consider that Ecma TC45's
Programme of Work included the goal of:
....enabling the implementation of the Office Open XML Formats by a wide set of tools and platforms in order to foster interoperability across office productivity applications and with line-of-business systems.
How exactly does the OOXML specification foster this interoperability when it ignores relevant web standards like MathML (and SVG and XForms)?
Microsoft's typical argument is to say that the existing standards are inadequate, that Microsoft users expect more, that they need more features, that this is because they need to deal with billions of documents and trillions of dollars, etc. But this rings hollow when talking about math. An examination of the history of mathematical notation demonstrates, as you may already know, that mathematical notation is not exactly experiencing a high rate-of-change. Equations, as used in math and sciences, for the most part use the same notation they did 100 years ago, and many parts of notation are 200-300 years old. Certainly there is no essential change in notation since 1999, when MathML was created.
Now if Microsoft had merely wanted to create a proprietary format for equations and use that in Word in order to trap their customers onto that platform, then I'd simply say that's not my concern and I'd blog about my heirloom tomatoes or something else. But when this shows up in a nominally open standard destined for approval by ISO, then this raises my eyebrows a little. The obvious choice would have been to simply reuse MathML. So, why are they creating, and standardizing a whole new math markup language? Are there no standards worth reusing? Will XPS replace PDF, VML replace SVG, Windows Media Photo format replace PNG, OMML replace MathML, and OOXML replace ODF? Let's say "No" to OMML and "Yes" to MathML, the math you can use.
August 19, 2006 12:34 PM
August 17, 2006
A survey presents a gloomy view of working in IT - but which planet did they survey?
August 17, 2006 12:28 PM
August 14, 2006
The Fair Trade products we saw being made in Bangladesh in March appear in Traidcraft's Autumn 2005 catalogue
August 14, 2006 08:02 PM
August 12, 2006
I’ve been cataloging my book collection, an accumulation of years of book buying by a wide-ranging and impulsive reader. I’m using
BookCat from FNProgramvare, a simple program with a killer feature for me — the ability to download book information, including author, title, publisher, copyright date, etc., based on ISBN or LOC codes. This promised to make the work much faster and removed the last excuse I had for leaving this task undone.
Any such cataloging effort inevitably becomes a journey into my past, as I recall when and where I purchased the book and what I learned from it. I also find the most curious things stuck between the pages of the books, old bookmarks from stores no longer in existence, shopping lists, an unpaid gas bill from 1993, a scrap of paper will a phone number but no name. In the end, having the database software did not bring the tremendous performance increase I had hoped for. The bottleneck is not the data entry — it is my day dreaming.
I came across my old copy of David Bohm’s
Quantum Mechanics, a well-worn paperback, not pretty to look at. But it is one of my Dover paperbacks, and I keep those. Dover Publications has a special place in my heart. Their paperback reprints of classic texts in mathematics and physics were my constant companions during my 20’s, and were part of something of a weekly ritual. Every Saturday, except in the dead of winter, I would walk the two miles to Harvard Square, go to Wordsworth bookstore (now gone), pick up a new book, and walk across the street to The Skewers (now also gone) for a falafel sandwich, or perhaps to Elsie’s (alas no more) for an Eslie Burger and a knish. I’d eat and read, and then head over to JFK Park (still here) and read some more, and then walk home, or more likely take the #86 back to Somerville.
Helmholtz’s
On the Sensation of Tone, Weyl’s
Space, Time, Matter and Smith’s
A Source Book in Mathematics“, are books I remember in particular. I think I learned more in my years after Harvard than I did when I was there.
So, after musing over the creased covers of my misspent youth, I decided to see if Dover was still around and what they had had in their catalog today. A quick search revealed their
online store. I had them send there printed catalog to my home. (Sometimes I need to hold paper). I put in an order and a week later a box of books arrived.
I’m reading now
Games and Songs of American Children by William Wells Newell, a reprint of the 1903 edition. I find it fascinating to trace transmission of this part of culture from generation to generation, of games like “Tag”, “Button button who has the button?”, “The church and the steeple” or “Odd or even?” These games are not learned from teachers in a school, or read in a book, or typically even taught from parents. For the most part they are transmitted from child to child, from an older sibling, or a peer, through the most casual pathways. They defied every propriety of authority or hierarchy. Culture was supposed to be a top-down thing, from the elites to the masses, right? But yet, games like this have spread across the country and beyond without any overt effort. In a way, it is like Language.
So, that made me think about the “classic” children’s parody of Jingle Bells, the one with the words “Jingle Bells, Batman Smells/Robin Laid an Egg/The Batmobile lost a wheel/and the Joker got away”. I assume there is no part of this country where these words are not known to every child. But it exists in no songbook. What great rhapsode first sung these words, and when and where was it done? How fast did it travel? I think if a sufficient survey was done of adults of various ages, as to when and where they recall first hearing these lyrics, one could attempt a reconstruction of the migration of this bit of modern folklore. Those who heard it earliest would have heard it closer to its source.
August 12, 2006 03:17 PM
August 02, 2006
In this post, I will take another look at the Microsoft ODF Add-in debate, suggest some criteria for use in evaluating file format integration, and use those criteria to evaluate both Office 2007's support for the ODF formats, and OpenOffice's support for Microsoft's formats.
My examination of the ODF Add-in for Word (
here and
here) has sparked a spirited discussion on both sides of the issue. A
balanced view is given by Jason Brooks on eWeek.com:
It's certainly going too far to call Microsoft's currently lukewarm support for ODF a change of heart, but it is nonetheless an encouraging instance of Microsoft listening to its customers. We call on Microsoft to make way for ODF in the standard supported-file-formats list giving it at least the same stature as the formats of the suite's once-fierce rivals.
In that spirit I'd like to propose some evaluation criteria for what first-class file format integration looks like, so you'll recognize it when you see it. I'll use Word and ODF word processorr documents (.odt file extensions) as an example, but the points apply equally to other formats and other editors:
- Is the format support "in the box", installed and configured when you do a default install?
- When you open the default File/Open dialog (the one you get with the Control-O shortcut, the one we all know and have been using for 20 years), do ODF files show up? In other words, does the default file mask include *.odt, or can you at least easily select ODF from the drop-down list of file formats?
- If you create a new document in Word, and then type Control-S to save the document, is ODF available on the list of file formats you can save to?
- Can an end user or administrator (no coding required) make ODF be the default format for saving documents?
- If you open an ODF document, and change it and then Control-S to save it, will this occur?Or will it save to some other format? Or will you get an error?
- Is support integrated into the Windows shell via the registry, so you can double-click on an ODF file on the desktop, in a folder or as an email attachment and it will automatically launch in Word? If you are like me, 90% of the time you are not opening a document from within Word, but you are launching Word with a file in this manner
Is there anything here I'm missing?
Let's compare, using the above criteria, how well Word's DOC format is treated in OpenOffice 2.0.3, and how ODF is treated in Word 2007 beta 2:
| Criterion |
DOC Format in OpenOffice |
ODF Format in Word |
| 1. Format supported in default install |
Yes. |
No. Requires a download and install of separate, unsupported Add-in. |
| 2. File Open integration |
Yes. |
No. ODF is not listed in the default File Open dialog and doing a Control-O will not show ODF documents. However, ODF import is available in a separate menu item elsewhere in the menu system. |
| 3. Save new document integration |
Yes. |
No. In fact no ODF save ability exists in the current version of the Add-in. There is a place holder for the ODF save operation, though it is on its own menu, and would not be shown when doing a simple Control-S to save a new document. |
| 4. Can be made the default format |
Yes. |
No. Although other non-Microsoft formats, such as "Plain Text" can be made the default format, ODF cannot. |
| 5. Simple round-tripping |
Yes. |
No. When an ODF document is loaded, its name is automatically changed and it is made read-only. So loading sampler.odt results in Word having a read-only version of sampler_tmp.docx. Attempting a simple Control-S to save will give an error. |
| 6. Shell integration |
Yes. |
No. |
Once again, the open source community wins. Not only is the fidelity of OpenOffice's support for MS Office formats higher, but they provide much closer integration of these competing formats.
I'm reading many explanations and excuses for why Office's support for ODF is the way it is. Here is a selection to ponder:
Brian Jones, a Program Manager for MS Office, said of the Add-in support:
It's directly exposed in the UI. We're even going to make it really easy to initially discover the download. We already need to do this for XPS and PDF, so we'll also do it for ODF. There will be a menu item directly on the file menu that takes to you a site where you can download different interoperability formats (like PDF, XPS, and now ODF).
I guess we differ how we define "directly exposed" and "really easy". IMHO, the easiest way to make this easy to find would be to install it with Office and put it in the normal place in the menus.
Also, in Office 2007 Beta 2, which I have in front of me, PDF and XPS are in the normal File Save and File Save As menus, not treated separately. I understand that there is a dispute with Adobe and so you are deciding to move the PDF and the competing XPS options out of the main File Save dialog, but that just proves my point. This is clearly a policy decision not a technical restriction. The fact is that PDF and XPS both work fine where they are in the File Save menu in Office 2007 beta 2.
Brian Jones again:
We already have the PDF and XPS support for Office 2007 users that unfortunately had to be separated out of the product and instead offered as a free download.
I agree that this is unfortunate. Full integration should mean it is included in the product and supported in the usual places. I'll take your world that PDF had to be taken out for non-technical reasons. But what prevents ODF from being integrated at that level?
And Jones on Interoperability by Design:
You see a lot of folks talk about interoperability, but often they just don't mean the same thing. From our perspective it's something we want to build directly into the products so that it just works.
That is a reasonable goal. I like it. By this definition, will we ever see a Microsoft-sponsored effort, open source or otherwise, to make ODF so it it is built "directly into the product so that it just works"? As pointed out above, a bunch of open source developers have already given this level of support to Office formats in OpenOffice. Isn't it embarrassing to be unable to accomplish the same task in Office 2007?
Patrick Schmid is a Microsoft Certified Systems Engineer who has obvious deep knowledge of Office Add-ins and customizations. He writes:
It is possible to write a custom file import/export converter for Word. This would add the file type supported by the converter to the file type lists in the Open and Save As dialogs. Unfortunately, this is not an option for the ODF translator project.
I will accept Schmid's technical appraisal of Microsoft's ODF Add-in, since he obviously knows far more about these API's than I do. However, this limitation appears to me to be a chosen limitation based on how this functionality was designed. Microsoft for years has provided import/export support for other file formats, often competing file formats, and they have always put them in the normal File Open/File Save dialogs. Why the sudden change? You can't hide behind limitations caused by choices that you choose voluntarily when other less constrained choices were available and in fact more typical.
Further:
The Open & Save As dialogs cannot be customized: There simply is no way for an add-in to add another file format to the file type list in those dialogs. I checked this with the Office beta team just to be sure.
There is no way to do this? When the Open Document Foundation responded to the Commonwealth of Massachusetts's RFI requesting info about the feasibility of an ODF Plugin, their response included screen shots of what appears to be the File Open/File Save dialogs in MS Office allowing the read and write of ODF files, side by side with the built-in formats like DOC. I hope this will not prove to be another embarrassment, where open source developers accomplish another task which Microsoft says is impossible.
Schmid further writes:
Why should MS waste resources on providing one particular feature for add-in developers that most Office add-in developers (all not affiliated with Microsoft) would put at the very bottom of their wish list?
Keep in mind that a single ODF Add-in could satisfy millions of customers. So we shouldn't count the value by the number of add-ins which could be written, but by the number of end-users who would use the add-in.
Stay tuned. I don't think we've heard the last of this issue. In particular I'd like to hear more about this Open Document Foundation Plugin, and the closer integration they illustrated in their RFI response.
August 02, 2006 12:08 PM
July 26, 2006
Brian Jones in his
blog entry of 11 July 2006, comments on their recently announced ODF Translator:
It's directly exposed in the UI. We're even going to make it really easy to initially discover the download. We already need to do this for XPS and PDF, so we'll also do it for ODF. There will be a menu item directly on the file menu that takes to you a site where you can download different interoperability formats (like PDF, XPS, and now ODF).
Heck, if you wanted to be even more hardcore, the Office object model allows you to capture the save event. So if you wanted to you could make it so that anytime you hit save you always used the ODF format, just by capturing the save event and overriding it. I'm not expecting folks to do that, but it does show just how extensible Office really is.
One might ask, is it a “hardcore” view to want ODF to be the default format for documents saved in Office? Isn’t this exactly what Massachusetts ITD requested in their
RFI?
What Jones does not say is that Word 2007 puts the ODF format at a disadvantage, making it harder than necessary to work with. Although end users are given a simple and direct UI for changing the default file format in Word 2007 to other file formats such as RTF, DOC or even ASCII text, ODF is not allowed as a default. Why should ODF users be forced to use “hardcore” programming to capture the “save event” to accomplish this same task?
Let’s take a look at the UI we’re given. Screen shots are based on Word 2007 Beta 2, and the
ODF Add-In for Word 2007.
Launch Word, create a document and try to save it, using the File Save menu, or the age-old familiar short cut, Control-S. What do you get? See the following screen shot for the familiar File Save dialog. Although Microsoft formats like DOCX, DOC and XPS are available, as well as export formats like PDF, HTML and Plain Text, you will not find ODF listed.
One new twist is the “Tools” button added to the Save As dialog. Pressing that reveals new options including something called “Save Options” which looks like this:
Here we see how Microsoft treats the file formats it favors with first-class support. Word 2007 allows you to choose which file format will be the default format when you save a document. You can keep the default format (Draft Office Open XML) or choose the legacy binary DOC format, HTML, or older formats like RTF or even Plain Text. But you will not find the ISO OpenDocument Format on this list.
So the question to ask is why Microsoft integrates ODF in a way which treats it as a 2nd class citizen, treated less favorably than even Plain Text?
- ODF cannot be made the default format
- ODF documents can not be round-tripped
- ODF documents are not accessible via the familiar keyboard shortcuts for opening and saving files (Control-O and Control-S)
- ODF documents pay a performance penalty for having to be indirectly converted via Draft Office Open XML rather than via native support
[ 7/2/6/2006 The integration discussion continues here]
July 26, 2006 08:27 PM
July 24, 2006
If I had know I was going to be
Groklaw'ed, I would have spruced up the place first and prepared for company! Thanks to all for the overwhelming expression of interest in these topics.
This blog is generated by Blogger, and published via ftp to my site. This blog is still quite young and you will continue you see things moving around a bit as I find out what works well.
Recent changes:
- I had misconfigured some Blogger settings, causing my feed URL to be incorrect. So, if you subscribed before 7/20 then you'll want to re-subscribe.
- I'm auto-converting Blogger's default Atom 0.3 feed to Atom 1.0. Thanks to the Sultan of Syndication, Sam Ruby, for help with that.
- I've added a brief capsule bio linked to from the sidebar. My contact info is there as well.
- I've also added a blogroll of sites which I find indispensable for keeping up with news related to ODF. I hope you find them as informative as I do.
I plan on writing additional essays related to ISO ODF and the draft Ecma OOXML. Expect to see one or two a week. There are already several bloggers who cover the universe of ODF news/happenings. Rather than repeat their good work, I will try to deal with technical issues in depth, with an emphasis on clearing the air of some of the FUD out there. I'll also try to keep it fun. If there are any topics you especially would like to hear, please let me know.
July 24, 2006 07:17 PM
July 16, 2006
In the
last installment I looked at the way the ODF Add-in for Word 2007 integrates into the Word UI. Now let's drill down into an actual conversion and see what fidelity we get.
I downloaded the code from
SourceForce and installed on a machine running the Office 2007 beta 2. The Add-in pre-reqs the .NET 2.0 runtime, an additional 22MB download. The current version only supports reading ODF documents, not writing, and only handles the word processor ODF format.
Now for fidelity. Since you may not all have Office 2007 beta 2 installed, I'm going to show you the fidelity via PDF exports. In all cases I manually verified that the PDF output was identical to what I saw on the screen, every error is real, nothing introduced by the PDF export process.
First up is a document I call "the sampler". It has a little bit of all the basic word processor formatting, fonts, alignment, nested tables, graphics, other character sets, headers/footers, images, captions, etc. It is not intended to be a particularly hard test of document conversion, but a basic test of core functionality.
So, here is the sampler, in the original ODF format, as well as the PDF rendering of it in OpenOffice 2.0.3, where it was originally created.
I then exported that file from OpenOffice to Word format. This demonstrates the quality of conversion users already get when running OpenOffice. Here is is in DOC and PDF exported after loaded the DOC file in Word 2007 beta 2.
Good, but not perfect. Some differences:
Again, that is the OpenOffice --> Word conversion we all have available for free today in open source code. Since DOC is a proprietary binary format with inadequate publicly-available documentation, this level of fidelity is impressive. So moving from ISO ODF to Draft Office Open XML should be that much easier, especially since the target format is voluminously documented (4,000 pages and growing), and the writers of the translator are receiving technical assistance from Microsoft.
Let's take a look. From within Word 2007 (beta 2) I use the ODF Add-in to load the sampler ODF file, and get something that looks like this PDF.
I won't characterize it but to say it fared less well than I expected. Problems include:
- headers/footers dropped (data loss)
- bullet list indentation ignored
- number list indentation ignored
- table dimensions messed up
- caption for the graphics sized and positioned incorrectly
Whether these are all bugs or merely functional limitations is an interesting question. There is a Functional Specification document available on SourceForge for the Add-in which lists these requirement:
2.1.1.1. Basic Formatting
Here is the list of formatting items that the Add-in and command line translator would keep intact. The first 10 in the list are must haves and the last 4 (number 11 to 14) are good to have items of formatting.
- Bold
- Italics
- Underline
- Bulleting
- Numbering
- Indentation
- Alignment (Left, Center, Right)
- Font size
- Font face
- Tabs
- Tables
- Font color
- Highlights
- Background colors
Tables are "nice to have"? I'd hope so! This does not give me the impression that full fidelity is in their plans. Forget about scripts and macros. They are not even planning on tables or font colors. I hope I am wrong or misinterpreting their plans here, but that is the requirements document they have posted.
July 16, 2006 01:29 PM
July 14, 2006

The word is “deaccession”, a fancy word for when a museum sells off parts of its permanent collection. Why does this happen? For many reasons, for example, the musuem may have received a bequest that was outside the parameters of its collection, it may have acquired items in the past that are now outside of the museum’s mission, or it may sell off some lesser masterpieces in order to raise funds for acquire a more significant piece of art. In any case, the Boston Museum of Fine Arts deaccessioned a number of ancient coins, one of which I was able to acquire, and which you see above. A close up is
here.
The obverse of the coin features a bust of Zeus/Ammon facing right. This was a composite god, conflating the chief Egyptian and Greek deities.
The reverse shows an Eagle grasping a thunder bolt, with a cornucopia under the rear wing. The legend reads
PTOLEMAIOU BASILEWS or “of Ptolemy, (the) King”.
This particular coin type is a well-known type from Ptolemy IV, who reigned from 221 BC to 204 BC. The Ptolemies were the Greek/Macedonian rulers of Egypt in the period after the death of Alexander the Great and before the rise of Roman control. By all accounts Ptolemy IV was an ineffectual leader, more interested in orgiastic rituals than ruling the nation. His one notable military victory was at the Battle of Raphia in 217 BC where he defeated the troops of the Seleucid King Antiochus III. In this battle, Ptolemy supplemented his Greek army with native Egyptians trained as phalangites. This infantry advantage proved decisive, and Ptolemy won the day, keeping Syria and Palestine in Egyptian hands. This was a mixed blessing, since this dynasty of foreign rulers now had to contend with armed and trained Egyptians at home, as well as external threats.
The reign of Ptolemy IV, including the Battle of Raphia, as seen from the perspective of an Egyptian Jew, is told in
3 Maccabees, a book canonical to the Bibles of Eastern Orthodox churches, though apocryphal to others.
One last look at the coin. Notice the “E” between the eagle’s legs? This a ”regnal date”, giving the year according to the year of his reign. Epsilon (E) was the 5th letter in the Greek alphabet, so this would correspond to 217BC, the year of the Battle of Raphia. So, a nice piece of history.
July 14, 2006 12:24 PM
July 09, 2006
John Maed had a great idea today on his blog. He thinks that spam should become more positive so you could start your day with inbox full of positive messages. I would personally love to see more subjects like “Have a wonderful day!” and maybe just “Smile, it’s a nice day”.
July 09, 2006 08:41 PM
A few days ago heroinewarrior released Cinelerra 2.1. So I am already seeing questions when there will be Ubuntu packages. The answer is the same as the on CVS cinelerra mailing list:
On tor, 2006-07-04 at 18:28 -0400, Computer Lists wrote:
> So... should I move to 2.1 or stick with the "CVS" version? I just
> spent a lot of time moving to the devel version because 2.0 had some
> problems and missing features I wanted. Is 2.1 based off of a recent
> build from the devel version?
you would most probably want to wait for 2.1 changes to be merged to
SVN...
timeframe of that is however completely unknown, since it is very hard
to merge such a big patch whole at once, taking into account all the
divergencies...
bye
andraz
July 09, 2006 11:31 AM
July 05, 2006
Today I got SMS with results of exam and it said that I passed. This means that I have now 7 of 9 classes done which I can already enroll in my last year of university. Normally that wouldn’t be anything special, but I had to pass the year in June/July because I’m already in Sweden on 31. July and can not finish the year in September.
So I can finally sleep easily now that I know that I have everything needed for my year as exchange student at Royal Institute of Technology. After this week is finished I’ll finally have some more time for hacking fun stuff like working on Debian and Ubuntu packages and preparing some chroot’s for bmsleight. Also more Django coding is waiting for me, especially prevoz.org rewrite.
July 05, 2006 10:25 PM
July 02, 2006
Somehow I always forget the exact URL of Bigwhale’s blog. So I have to google it. Imagine my surprise when I tried to google his page today and google returned only two results. So, is anyone else seeing such strange things happening with Google lately?
July 02, 2006 12:34 PM
July 01, 2006
Mac OS X (X11)
- found why OpenOffice.org didn't start on Tiger (some X11 libs corrupted)
- created macosxkbd cws ( should fix #i58750# ) + patch including gtk fix. Code needs review
- fixed #i66881# Will save some time and place
another cws to create: macosxfixes04 including #i62119# and maybe #i65056#
Linux PowerPC version :
- created linuxppcrpm cws ( #i66719# )
Prepared meeting. Thank's to Shaun Mc Donald for his help.
Todo : save time for native port and hollidays
July 01, 2006 03:44 PM
Originally uploaded by Cuhalev Jure.
Length: 13km
Road: good
July 01, 2006 02:29 PM
February 23, 2006
I find it interesting to take a look back at the commemorative stamps issued in 1956. What do we choose to remember, and how do we remember it?
For example, 1956 was the 100th anniversary of the the birth of Booker T. Washington, a great leader in education and civil rights, founder of the Tuskegee Institute in Alabama. He was first honored on a U.S. postage stamp in the Famous Americans series of 1940, with a head and shoulders portrait.
But in 1956, the centennial celebration, how was Booker T. Washington honored?

This stamp, issued April 5th, 1956 was designed by Charles R. Chickering, artist at the Bureau of Engraving and Printing. When I first saw this stamp, my reaction was immediate. Where is the portrait? 1956 was the centennial of the birth of the man, not the anniversary of a log cabin. I found this odd.
The other person honored in 1956 was Benjamin Franklin, on the 250th anniversary of his birth. This design in bright carmine (also by Chickering) was based on the painting "Franklin Taking Electricity from the Sky" by Benjamin West and was issued on January 17th, 1956.

2006 is the 300th anniversary of Franklin's birth, and a set of 4 stamps is due to be issued April 4th. You can see the planned designs
here.
February 23, 2006 09:58 PM
January 19, 2006
The
Edge Foundation’s 2006 question is framed as:
WHAT IS YOUR DANGEROUS IDEA?
The history of science is replete with discoveries that were considered socially, morally, or emotionally dangerous in their time; the Copernican and Darwinian revolutions are the most obvious. What is your dangerous idea? An idea you think about (not necessarily one you originated) that is dangerous not because it is assumed to be false, but because it might be true?
You can read the answers from 120 luminaries from many disciplines
here. Many of respondents fled to the polar banalities of atheism, solipism or pantheism, and there is little here that is really dangerous, subversive, or would even be unnseemly at Unitarian prayer breakfast.
But read and judge for yourself. And think of what your most dangerous idea is. I’ll share mine.
The last few years have seen great advances in genetics, the decoding of the human genome, the discovery of gene thearapies, etc. The prospects of curing genetic diseases by formulating designer drugs is no longer the stuff of science fiction. That some diseases are associated with certain ethnic or racial groups is also well-established. For example, Ashkeazic Jews have a greater probability of being born with Niemann-Pick, Gaucher, or Tay-Sachs diseases. Men on the Caribbean island of Tobago have a 3-fold increase in the likelihood of getting prostate cancer due to an shared genetic mutation. Cystic fibrosis is more common among Norther Europeans. This is not to say that race or ethnicity is a genetic determination, but that certain generic mutations associated with certain diseases are more prevalent among certain subpopulations, and these subpopulations often break along racial and ethnic lines.
For a hundred bucks or so, I can take a
mail-order test in the privacy of my home to see if I have Native American ancestry, African ancestry or Jewish ancestry, including whether I have the
Cohanim gene.
Think of the implications of this. We can identify specific genetic markers that can be used to distinguish members of various human subpopulations. But this ability can be used for good or bad. Put it altogether and think evil. No, even more evil than that. Think Ultimate Evil. Unleash the demons of biological warfare. What in principle prevents one from creating a biological organism which targets a specific human subpopulation based on their genetics? For example, a targetted virus which would attack everyone of European ancestry, but would have no effect on the Chinese? The genocidal implications of this are enormous.
Churchill spoke of the danger of losing WWII and how we could “sink into the abyss of a new Dark Age made more sinister, and perhaps more protracted, by the lights of perverted science.” Certainly there is no shortage of ways to destroy the entire world with germs, with bombs, with climate changes, with microscopic blackholes, etc. Our inability to prevent such destructions proves that Man is foolish. But our ability to destroy a fraction of our word, in a clinically targetted, racially motivated way — that may prove that Man is Evil, and that is my most dangerous idea.
January 19, 2006 03:51 AM
A few thoughts on the Epitheton Ornans, or ornamental epithet. This is more than a nickname, but a formalized word or phrase associated with a person. Classical epic poetry makes heavy use of this rhetorical device. For example, in Homer Achilles is often referred to as “podas okus” or “swift-footed”, whereas Agamemnon is often “anax andron” or “ruler of men”. There is internal evidence that these poems used a stock list of epithets of different lengths and stress paterns to fit into whatever metrical context was needed. In this way, the epithets could aid improvized oral performance, much as a jazz musician has a repetoire of riffs and chord progressions at his command which can be inserted to fill out a phrase.
The Romans allowed the honor of an “agnomen” for significant military victories. So Publius Cornelius Scipio, after defeating the Carthaginian Hannibal, became Scipio Africanus. Over the centuries, this trend escalated. So, by the 4th Century A.D., we have awe-inspiring names such as “Imperator Constantinus Maximus Augustus Persicus maximus, Germanicus maximus, Sarmaticus maximus, Britannicus maximus, Adiabenicus maximus, Medicus maximus, Gothicus maximus, Cappadocicus maximus, Arabicus maximus, Armenicus maximus, Dacicus maximus”. (Today We just call him “Constantine the Great” which is a great time-saver)
The trend continued. If you’ve seen an old British penny, from 100 years ago, you would read the legend “VICTORIA D G BRITT REG F D”, short for “Victoria, by the Grace of God, Queen of England, Defender of the Faith”.
But the use of epithets has been on the wane for many years now, at least in the optimistic parts of the world. North Korea may have its “Dear Leader” and the late “Great Leader”, but we never even considered formally naming Eisenhower “The German Slayer”. We ended up with “Ike”. I guess we like our leaders to be mere men, and not gods. The Cult of Personality is difficult to maintain in a democracy with a free press. “No man is a hero to his butler”.
Sure, we have our little nicknames, “The Artist formally known as Prince”, “Iron” Mike Tyson or the “Scud Stud”, but that is done in jest, or in the entertainment world (which amounts to the same thing). We will never see “Scud Stud” carved in marble or engraved in brass.
But once a year, on this date (or the nearest Monday) I am reminded of the most prominent example of epitheton ornans in common use today. I refer to the ubiquitous use of the phrase “Slain Civil Rights Leader”. The fact that I do not need to name the owner of this epithet demonstrates its currency. A search of Google News shows almost
1,500 uses of this phrase in recent press clips. This epithet is so tightly associated with him that can be used as a substitue for his name, much as a medieval scholar could speak of “the Philosopher” to refer to Aristotle without ambiguity.
I’m trying to think of any other prominent examples of such epithets in common use today. I can’t think of any. Can you?
One wonders how long this epithet will remain? Will it outlast the generation that heard his message and headed his Dream? We can hope so. But I do note that in the generation after the assasinations of Lincoln, Garfield and McKinnley, all three were popularly acclaimed with the epithet “our martyred president”. But a search of Google News shows zero hits for “martyred president”, though there are 271 hits for “President Lincoln”.
January 19, 2006 03:23 AM
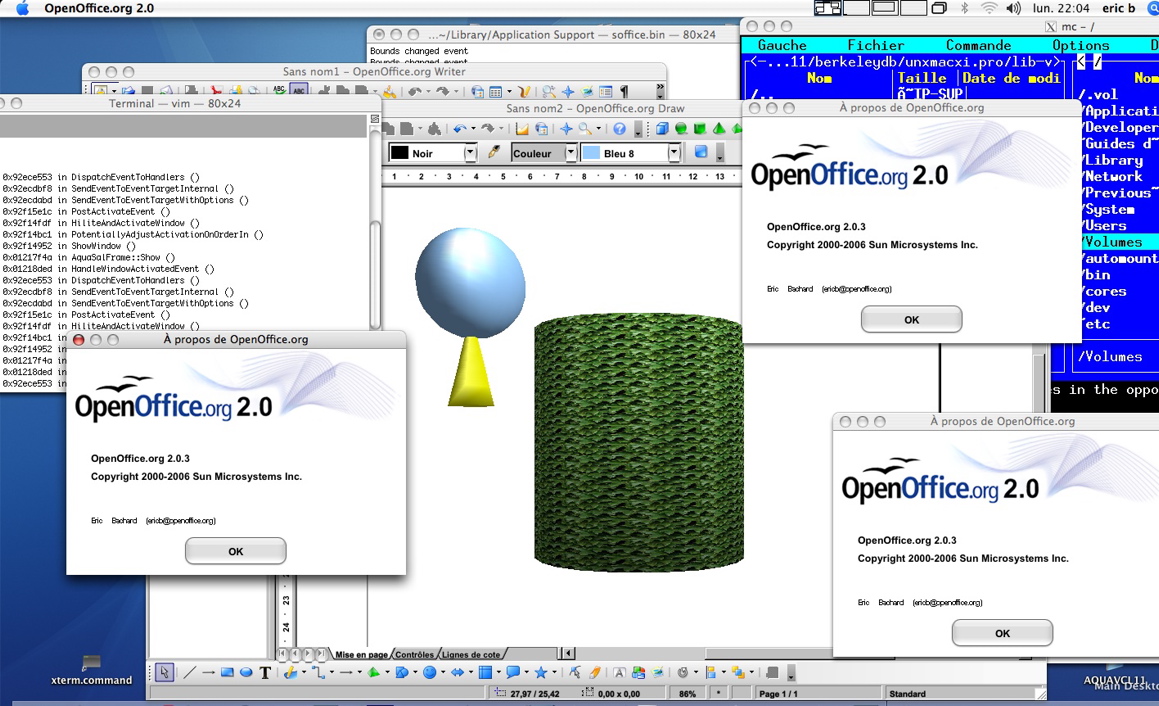
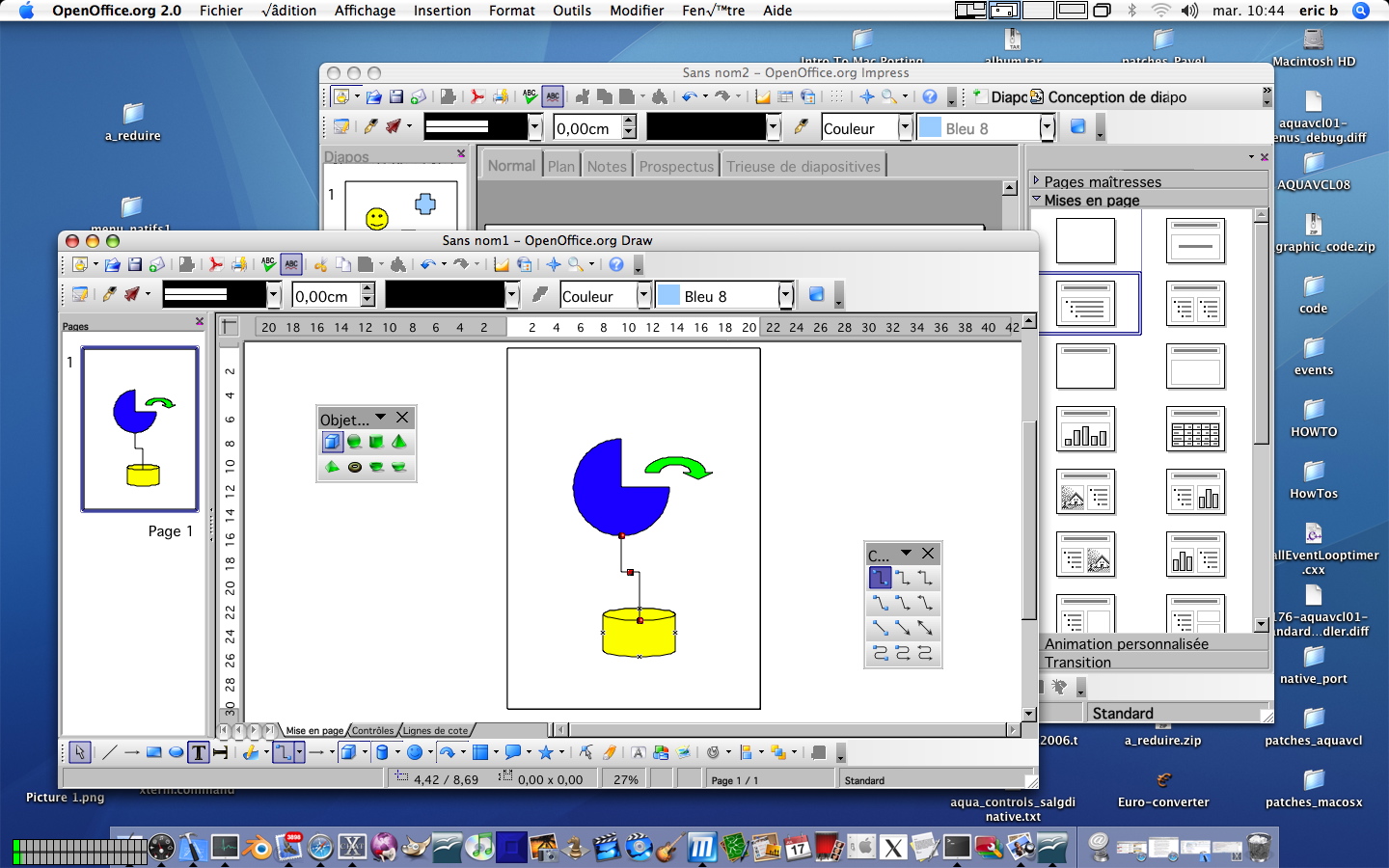
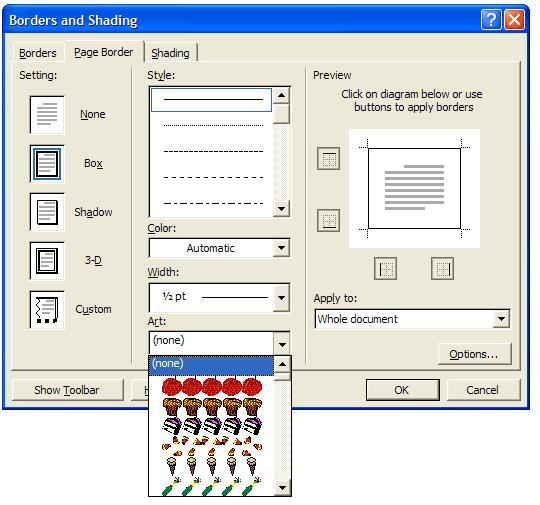
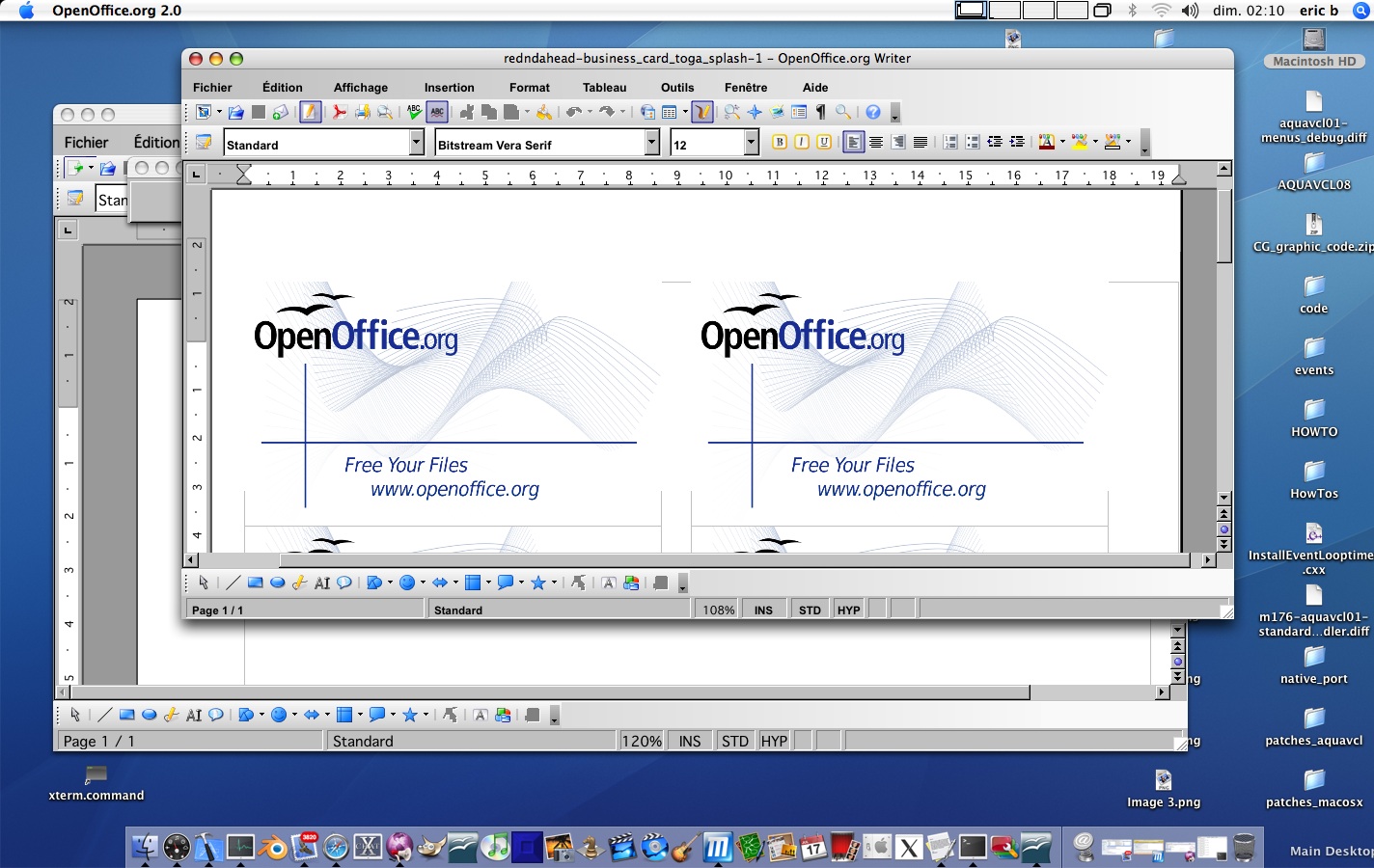



{kind=link}
{kind=link}